
整理|刘杨楠
编辑|王博
“2024年,从GPT到GPT Zero会是重大的阶段性成果,我们相信这一天会在不久的未来到来。”
在2月29日举行的2024中关村论坛系列活动——第二届北京人工智能产业创新发展大会上,清华大学基础大模型研究中心主任、清华大学计算机系WeBank讲席教授唐杰发表了演讲,并对大模型在2024年的发展给出了自己的判断。
唐杰在中国人工智能领域的重要性无需多言,在OpenAI的文生视频模型Sora震惊全球后,包括「甲子光年」在内的很多在场观众都很期待,作为国产大模型研究先驱学者的唐杰,对Sora有什么看法,对未来又有怎样的判断?
唐杰认为Sora“可能是目前为止最好的文本到视频生成模型”,而针对由Scaling Law(规模法则)产生的智能涌现,他回应了两个当下颇具争议的问题:
Scaling law的尽头到了吗?
Scaling law的尽头是否就是AGI?
在他看来,2023年是大模型的实践应用落地之年,今年更多的大模型将开始全面面向AGI,“我非常坚信2024年将开启AGI元年。”
以下为唐杰演讲实录,原标题为《ChatGLM:从大模型到AGI的一点思考》,经「甲子光年」整理,有删改。
1.从“算法之战”到“大模型落地应用之战”
今天我带来的题目是《ChatGLM:从大模型到AGI的一点思考》。我们在清华大学各位老师和学校领导的支持下,成立了“人工智能基础模型研究中心”。我今天报告里讲到的几乎所有模型和算法都开源了。
刚才也有很多学者和产业界的朋友都提到了OpenAI,OpenAI确实引领了整个大模型的发展,其中有一个非常重要的时间节点,也是国际上比较公认的“大模型元年”——2020年,GPT-3的发布。
GPT-3发布之前,虽然GPT-2比较小,但GPT-2能力非常强,基本上能在一句话里把主谓宾、状语、定语这些要素生成得比较不错,而且非常流畅,但它还没有实现智能推理。很多大模型到现在也还没有涌现智能。
GPT-3一下就到1750亿参数规模,可能到现在为止,国内包括美国很多公司能突破这个参数体量的还比较少。
原因各有不同,有的是为了保证推理速度,有的是因为稠密模型在知识量方面已经非常强了,所以国际公认2020年是大模型元年。
直到2023年3月14日,GPT-4的出现让大模型迎来真正的爆发。
GPT-4大大推高了ChatGPT的能力。2022年11月30日,ChatGPT的第一个版本基本上算demo,能力还没有那么强,很多用户进来玩了一段时间之后又流失了。GPT-4让大家看到大模型作为工具基本上是可用的。GPT-4不仅大大提高了文字生成能力,还提高了逻辑推理、数学甚至微积分能力。
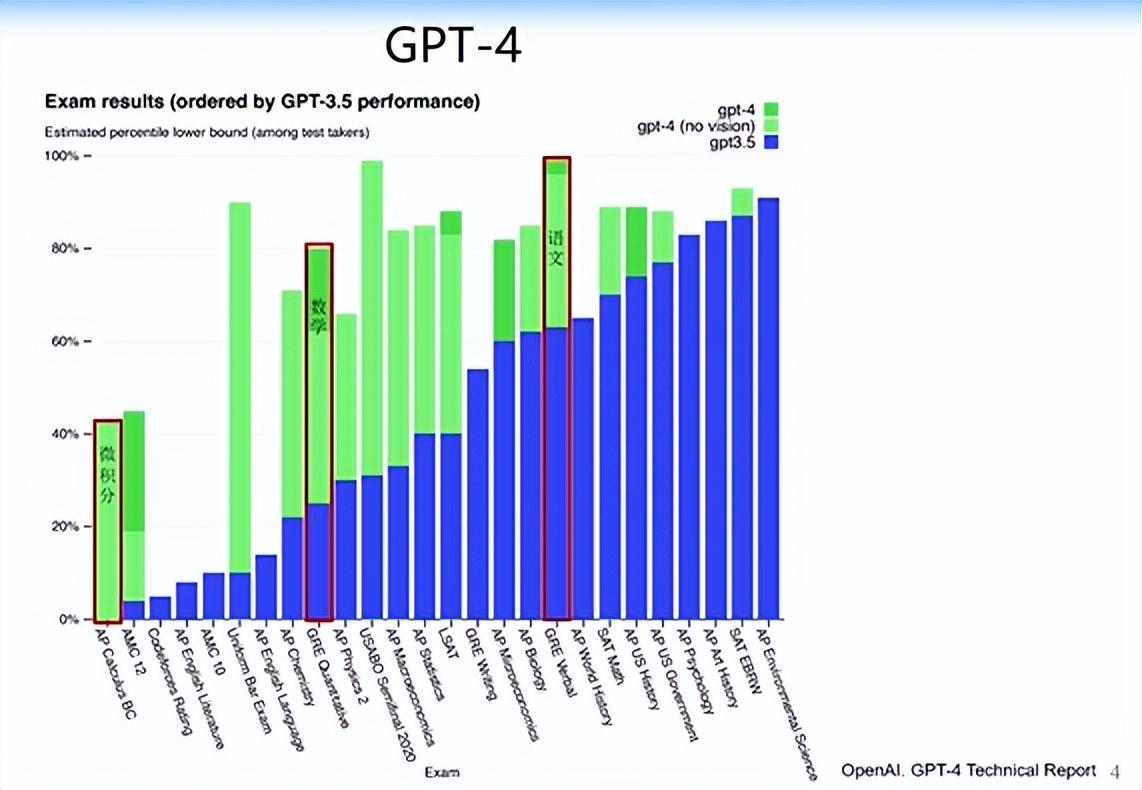
GPT-4还有很强的图文识别能力。给定一张图(下图左侧图片),GPT-4可以识别出共有三张图,并且能针对每张图给出非常生动的描述。

2023年11月6日,OpenAI发布GPTs,也就是智能体,使得大模型的应用门槛大大降低。我们可以用一些简单的自然语言,比如“请帮我们生成游戏”“帮我生成给小学生用的计算器”,不需要任何编程,操作系统可以帮你编程,还可以帮你从网上查找相关的信息,自动生成带界面的应用程序。
GPTs让很多人变成了大模型的开发者。到现在为止,互联网上可能有几百万开发者,甚至很多开发者应用,也就是一个智能体,通过自然语言处理,再通过自然语言放出去一句话,每天日活都可能到百万。今年过年期间,我们有开发者通过很简单的方式生成了很简单智能体应用,每天的token调用量可以达到几百亿。
最近OpenAI发布了Sora,这可能是目前为止最好的文本到视频生成模型。其实Meta的Emu也能做不错的视频生成,但是距离Sora还有一定差距。

我用这个案例的原因,是因为Bill (编者注:Bill Peebles)原来在Meta做相关研究,后来到OpenAI做出了非常惊艳的Sora。
综合以上,我们可以看到OpenAI在过去五年不同时期所做的事。
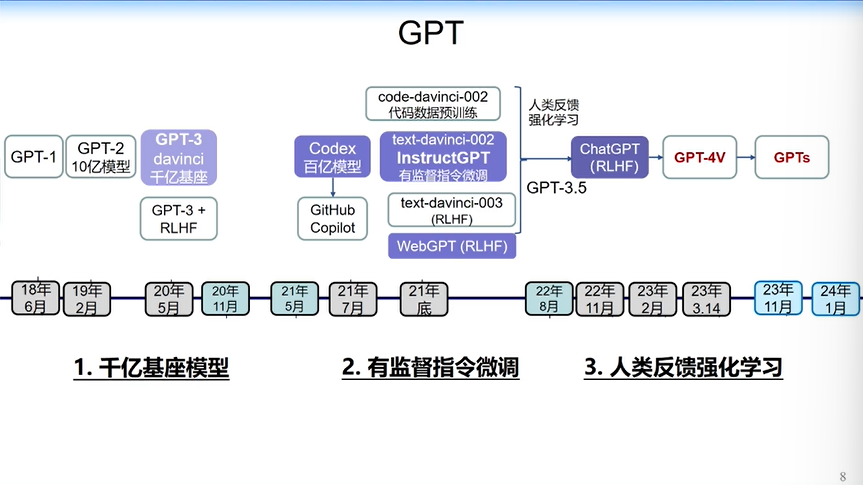
2018~2020年,基本在做核心算法的研究。同一时期,Google在做T5,各家分别做了不同的算法,但基本上都是在Transformer架构上做的,我把这个时期叫做“算法之战”。
2020~2022年,大家开始思考如何让这些模型更智能,并且跟人的行为align(对齐)起来,开始有监督的指令微调,教模型跟和人的行为、人的产业应用对齐。
2023年,大模型爆发以后,很多企业一开始没注意,但2023年6月份开始,从互联网企业到很多国央企、传统企业都开始布局大模型,有的用一些开源模型做微调,有的企业直接购买超大规模的底座模型开始做应用。
我认为2023年是大模型的实践应用落地之年,今年更多的大模型将开始全面面向AGI。
2.为什么大模型越来越智能?
为什么大模型变得越来越聪明、越智能?难道是因为数据大、算力大,计算量大吗?
答案是:“是的。”
正是因为数据、算力、计算量非常大,才使得训出来的模型越来越聪明。这就是我们经常听到的Scaling law(编者注:规模法则),Scaling law使得大模型具有一定的理论基础。
但我们回顾AI的发展,从早期的符号AI到感知智能,到今天我们已经进入认知智能时代,这几个时代都发生了什么变化?
符号AI实现了“知识的可搜索性”。无论是机器学习算法还是知识库、知识图谱都在做一件事,就是人类定义很多规则,让机器在规则里找到最优化的分界面或搜索结果。
而感知智能时代最重大的变化是深度学习的出现。深度学习就是给定一个样本,不需要人来定义,机器自动学出表示,解放了人类的定义。由机器、算法来决定什么样的表示最好,深度学习实现了“知识的可计算性”。计算机只能做计算,不能实现特别多丰富的语义。计算机真的理解我们了吗?不一定。计算机理论上没有理解能力,计算机真正能实现的是知识的表示,不需要人类告诉计算机知识应该怎么表示,规则应该怎么定,计算机能自动识别并表示知识。
但这个时代的不足,是你必须告诉计算机你要做什么任务,比如你要做人脸识别、杯子的识别、垃圾的识别。于是对于不同的识别任务,必须标注不同的数据,就像ImageNet一样。你给定了多少人工标注,你的精度就有多高。当时很多人都说“有多少人工,就有多少智能”。
近五年我们进入认知智能时代,你给定大量数据,机器学习的任务是机器自己定的。你给了很多文档,机器自动决定哪些地方学填空,哪些地方学摘要,哪些地方学下一句的生成。在这个时代,计算机实现了机器认知的“元学习”,自动学习目标,不需要人为给定样本的表示规则,也不需要给定他要学什么东西,它能够自动学习。
由此带来的重大变化是,当我们有简单的知识表示以后,比如我们给了知识一个向量表示,就可以做非常简单的计算。比如“中国减去北京等于日本减去东京”,我相信很多做机器学习或者有一点点人工智能基础的人都看了例子,从大模型对话的角度看,你问大模型“在日本跟中国的北京地位一样的城市是什么?”大模型就会自动回答是东京,看起来在计算上非常简单,但是它好像实现了推理能力。在此基础上,我们就可以逐渐实现更复杂的推理。
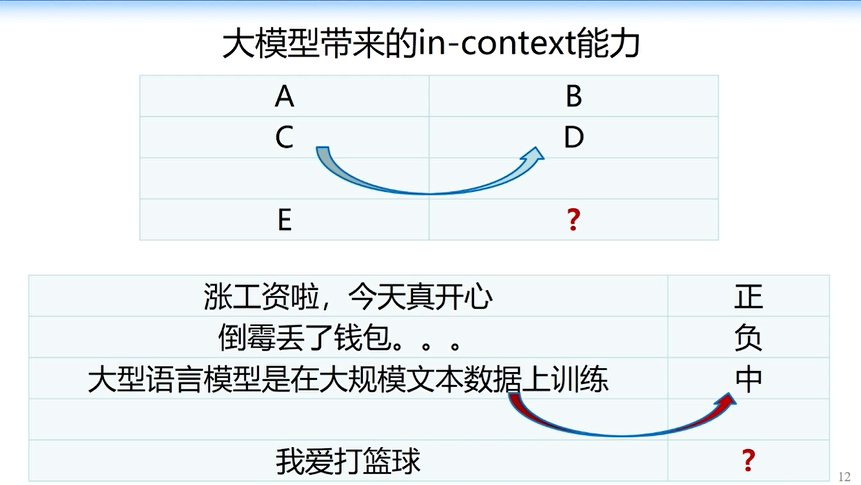
随着模型的增大,甚至能实现更复杂的能力。当我们给定一句话,大模型会把这句话映射到一个知识概念空间,比如我们给了problem,它把问题映射到concern上再做一定的推理。
再复杂一点,给定数学题,你可以教模型把数学的推理过程学出来。比如我给定上一道数学题,他学完推理过程后,能自动跳到下一道数学题,相当于你教了它一次以后,它可以求解下面数学题,这就是“in context learning” 能力的变迁。大模型一步一步把能力迁移后,能力越来越强,我们看起来就好像大模型在逐渐涌现出更多的能力,也就是“涌现的模型新能力”。

3.GLM:GPT之外的路径
2020年,“算法之战”结束,开始模型之战的时候, OpenAI基本上就不再公开所有的技术细节。今天我们看到的OpenAI所有的技术细节基本是大家猜的,或是大家通过猜来做实验,最后调试的结果,也由很多人是用LLaMA等开源模型调出来的。
我们团队非常希望在这个时代解密所有OpenAI做的东西。当然我们的解密也不一定百分之百正确,因为OpenAI并没有公开所有技术细节,我们只能通过猜测和性能比较。
过去几年我们把OpenAI做的所有事情基本上都做了个遍,提出了一个区别于GPT的算法——“GLM算法”。
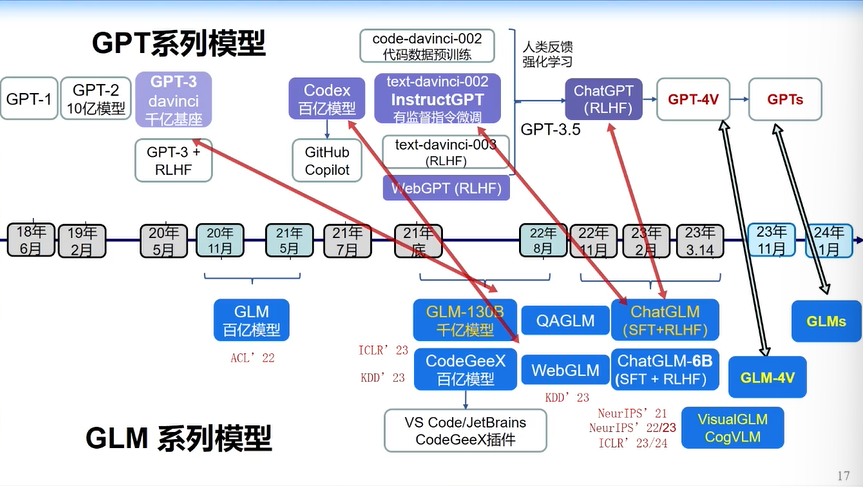
GLM算法把Bert和GPT合并在一起,使得它跟GPT有点不一样,但又比较相似的地方是,它学到的attention是半矩阵(如下图右下角所示),但是它又多了一点attention(如下图右上角所示),多的这一点使得GLM在某些任务上比GPT效果更好。
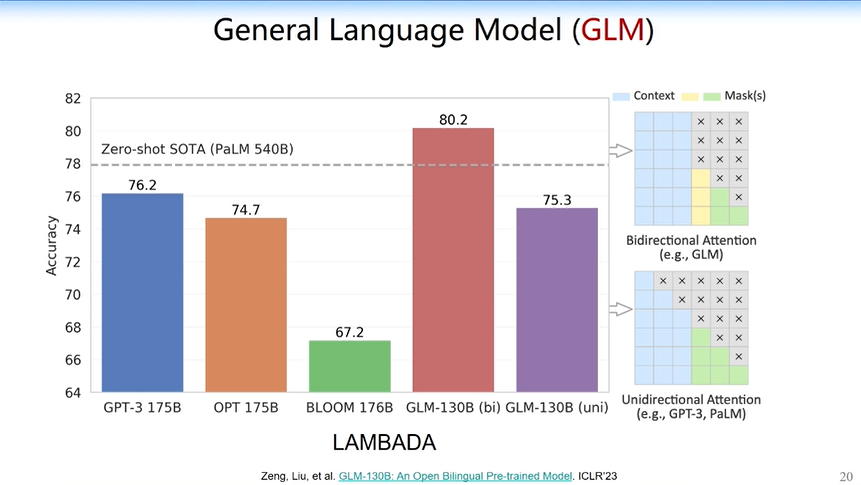
斯坦福做过一个全面的评测,我们的基座模型基本上在2022年跟GPT-3在一个水平。
有了基座模型我们就可以很容易地做对话模型。2023年2月,我们就推出了ChatGLM-130B,用1000多亿的基础模型迅速调出对话模型。对话模型中就有大家能看到的一些基础能力,比如对话、生成文字,甚至解决一些幻觉问题。
大家老说大模型有幻觉,但事实上人也有幻觉。你慢慢多教大模型几次,他的幻觉会越来越弱,所以现在大家已经不再说大模型的幻觉有多严重。
此外,在基础能力上,比如基础的英文能力和文字能力方面,我们新推出的GLM-4已经非常逼近GPT-4。
文生图方面我们最近推出了CogView3,可以非常好地捕捉文字中的语义信息。

有了这样的能力,我们就可以画一些动画:
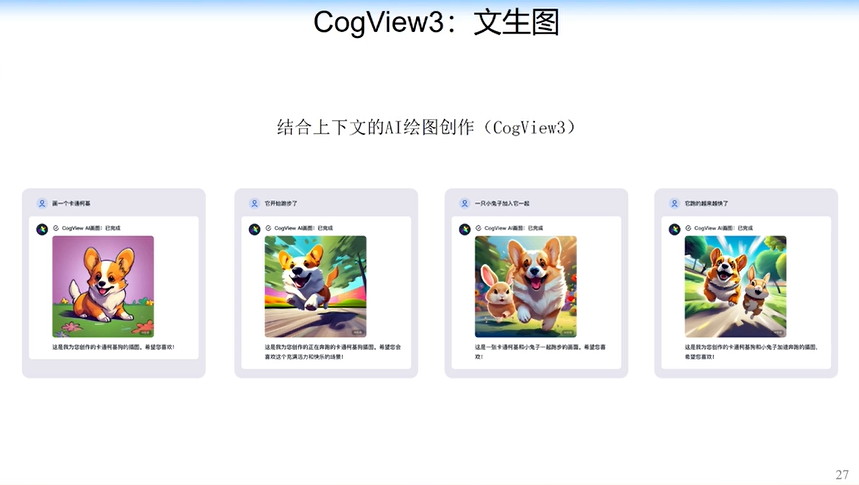
我们文生图的能力也大大提高。我们现在超越DALL-E了吗?我个人觉得还没有。但我们明显比一些开源模型的能力好很多,也在逼近DALL-E。
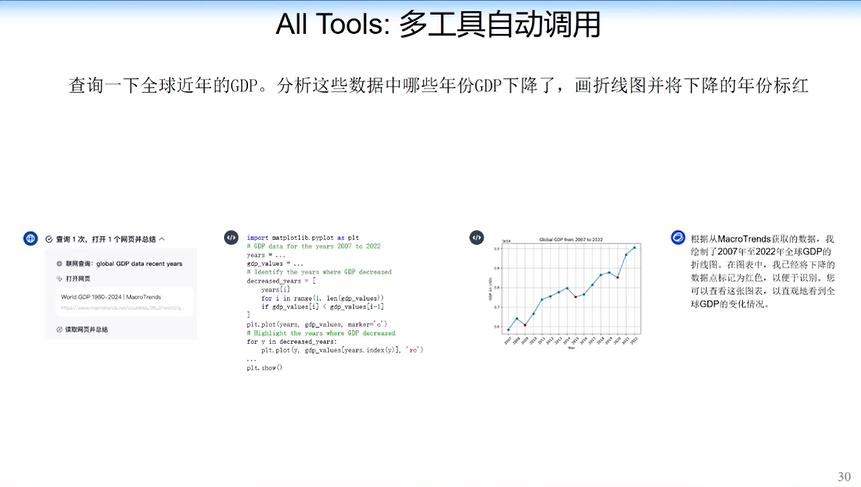
另外,我们最近经常提到的“All Tools”,也就是Agent能力也有提高。我们能够实现教模型自动写代码,自动在不同问题里调用搜索引擎或调用其他的求解器。
比如,查询全球各国GDP,分析这些GDP数据中哪一年下降了,用红色标出来,并画出曲线图。
最近Sora越来越火,我们之前也做了一点CogVideo的工作。当然现在的效果还远远不如Sora,所以我们最近也在加速。我们在21年、22年、23年分别发表了关于视觉生成和图片生成的相关文章。
这是两年前我们生成的结果:
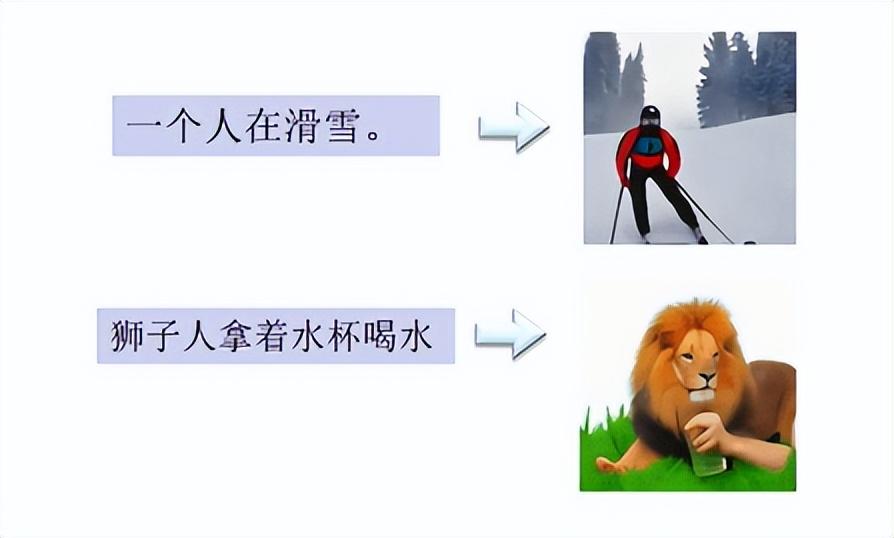
生成效果还不太好,但是语义捕捉已经不错了。比如,“狮子人拿着水杯喝水”,它可以生成狮子人,并且用手拿着水杯在喝水。当时生成的时长只有10s。最近我们正在不断提高模型能力,希望能够实现像Sora一样生成60s视频的能力。
有了这样的能力以后,我们就可以做很多智能体方面的工作。这是一些网友做的智能体。
这些智能体的制作过程非常简单,就是输入几句话,未来每一个人会成为智能体时代的开发者。
未来我们还希望把GLM-4的一些能力变成智能体OS。这是我们在手机上做的demo,你可以问它一句话,比如“把手机显示改成light模式”,大模型会自动查找手机上的“设置”按钮,点开它,再把“设置”里面的“display”找到,把它改成“light模式”。所有流程全部是机器自动做,不需要人工干预,也不需要设置任何的规则,这个模型我们也已经开源在网上。
我们希望所有的研究都以开放的方式促进国内甚至国际上的大语言模型研究,所以我们基本上把所有的模型都开源了。
4.坚信2024年将开启“AGI元年”
大模型发展的基石是Scaling law。由此衍生出两个问题:
Scaling law的尽头到了吗?
Scaling law的尽头是否就是AGI?
首先回答第一个问题,现在我们还远未到scaling law的尽头,数据量、计算量、参数量还远远不够。现在大部分模型可能都困在1000亿左右,而且很多模型还没到1000亿。因此,未来的scaling law还有很长远的路要走。
现在回答第二个问题,scaling law走到尽头不一定能实现AGI,但是肯定比现在的模型要聪明得多。
另外,人脑有多模态的感知和理解,有学习、记忆、陈述,我们有记忆系统、反思系统、逻辑推理系统,比如我们做完一件事情以后会反思,哪里做得不够好,能不能重做一下?这时你又会改进自己的规划系统和做事的规则。
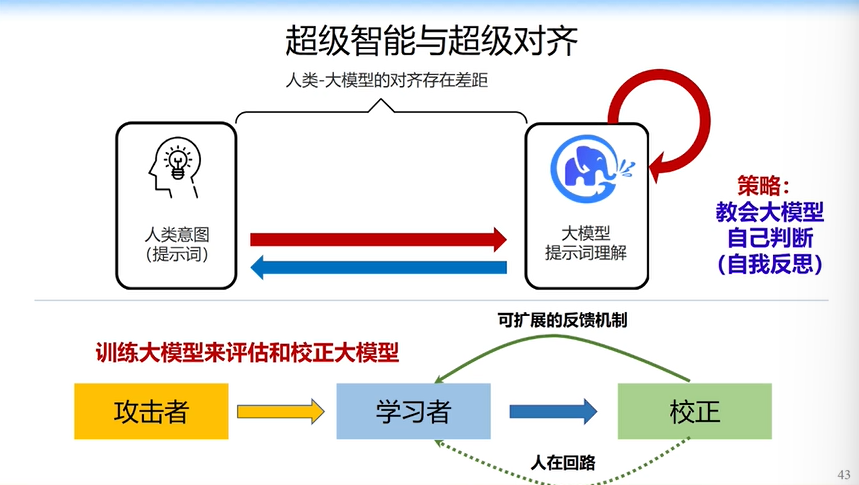
我们能否从人脑的认知角度出发,改进未来的AGI系统,使它变得更加智能?这是我们未来要思考的问题。在模型越来越聪明的同时,我们能不能让超级智能跟人类的价值观、道德观对齐?这是更重要的问题。否则如果未来AI超过人类,会不会对我们造成威胁?
我们现在做一些工作,让大模型自己教自己,并且自己和人的价值观对齐,教会大模型自己判断、自我反思,这是在国际上非常热的“超级对齐”和“超级智能”。
我非常坚信2024年将开启AGI元年。从今年开始,国际上很多学者都会来探索AGI。今年的终局是什么?
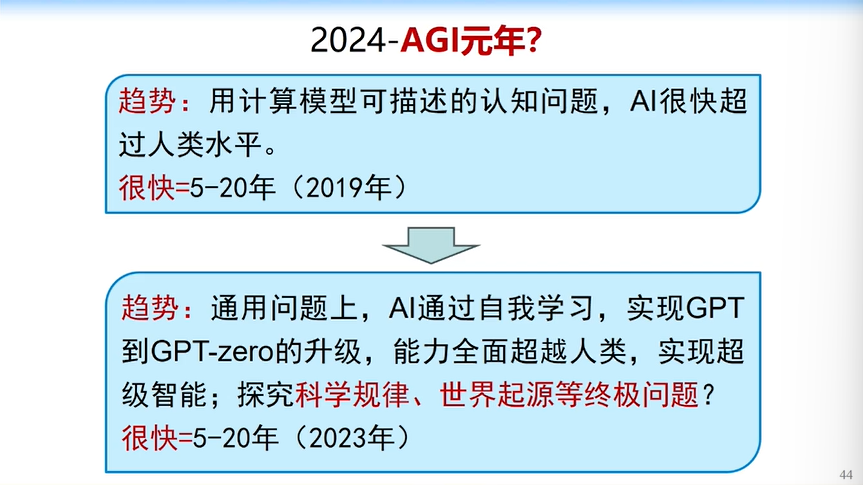
我认为今年的阶段性成果,是实现GPT到GPT Zero的进阶,即大模型可以自己教自己,不需要我们输入这么多数据,它会自己构造数据来教自己。
Sora已经有了些端倪,Sora通过游戏引擎构造了大量的数据,使得自己变得更聪明。但GPT到GPT Zero会是重大的阶段性成果,我们相信这一天会在不久的未来到来。未来GPT甚至可能会帮我们探索科学规律和世界起源这些终极问题。
总之,2020年是大模型元年,之前是“公元前世纪”,2020年之后我们经历了大模型的“模型之战”,还有“落地之战”。今年我们全面面向AGI,但是未来的AGI之路还很长。
以上是我的报告,感谢大家。
(封面图来源:大会主办方,文中配图来源:唐杰现场演讲PPT)

 2024-03-01
2024-03-01
 7636
7636 0
0 0
0 0
0

