设想一个场景。
一名工人在一家手机工厂工作,他每天负责组装手机。尽管他技艺高超,能够制造出高质量的手机,但这些手机并不属于他,他也不能决定这些手机如何被使用或分配。他对自己的劳动成果没有控制权,甚至可能买不起自己制造的手机。
这就是劳动者与劳动产品的异化。
《1844年经济学哲学手稿》是马克思研究政治经济学的第一部手稿,在这部手稿中,马克思运用异化范畴,得出了著名的“劳动异化”的概念。
180年后的今天,在国内某头部手机厂商的全数字化智能工厂里,一条产线搭建只需一天,一部手机诞生只需6秒。
人在生产过程中被异化后的投影,正在被机器人消除。
1.工厂里的新物种
其实,能根据编程指令进行重复性操作的“自动化工厂”早已屡见不鲜,但是能根据实时数据和环境变化做出智能决策和优化调整、实现自适应性和灵活性生产的“智能化工厂”的仍在发展中。
“一条产线搭建只需一天,一部手机诞生只需6秒”的背后,除了自动化之外,更重要的是智能化。
例如,把搭载了生成模型、目标检测模型、小样本学习、异常检测等混合视觉算法的机器人用于工业质检,可以显著提高检测缺陷的种类,降低落杀率、漏失率和CT所用时间。
除了质检场景外,搭载了不同大小模型的机械臂和工业机器人也可以用于装配、精密加工、喷涂、焊接等一系列工业生产的场景中,不仅能实现自主场景感知与任务规划,而且在柔性生产制造的场景中也能根据需求进行灵活的产线切换。
基于此,微亿智造CTO赵何博士提出了具身智能工业机器人(Embodied Intelligent Industrial Robots, EIIR)的概念——一种能够自主感知外在环境、自主规划任务、切换产线的工业机器人。
“EIIR需要替代的是人在生产过程中被异化后的投影,不是人的本质,更不是人的外形。”赵何说,“相比精确的自动化控制,EIIR可以实现真正的无人化生产。”
为什么具身智能机器人率先落地的场景是工业?
简单版本的回答是:可控。
复杂版本的回答是:具身智能机器人现在最大的问题在于算法(模型稳定性)和数据(泛化能力),开放的场景下对这两项能力的要求极高,现阶段的具身智能算法和数据还无法达到;而在封闭、单一的场景,不需要那么复杂的模型和那么强的泛化能力,让机器人做简单、重复的任务也足以解决问题、应对商业化的需求。
而工业场景,就是这种“封闭场景”和“简单、重复任务”的绝佳体现。
蓝驰创投董事总经理、合伙人曹巍将机器人工作的场景划分成了一个X轴为“场景复杂度”、Y轴为“任务操作复杂度”的坐标系,在该坐标系中,简单场景和低复杂度的任务包括中低精度螺丝紧固、上下料、巡检操作等,而当下弱人机共存、高度结构化的工业场景与此几乎100%契合。

曹巍分享具身智能机器人的落地场景,图片来源:「甲子光年」拍摄
赵何也表示,工业场景更多是一个人造的环境,讲求效率、精准度和可重复性。这样的场景不仅有利于数据和算法还未完善的具身智能大模型的落地,搭载了大小模型的更智能的机械臂更是极大提升了工业生产的效率,解决了工业领域人力成本高的问题。
然而,尽管当下很多企业在做“大模型上机械臂”的尝试,但是效果并不好,要么速度慢,要么动作稳定性差,要么就是不够智能化,无法精确完成视觉感知和柔性切线任务。
这就牵扯到了具身智能工业机器人最关键的问题:“小脑”。
2.技术瓶颈在“小脑”
作为具身智能机器人的一个分支,EIIR自然也有“大脑”和“小脑”。
简言之,“大脑”包含LLMs(Large Language Models)、VLMs(Vision Language Models)和VFMs(Vision Foundation Models),负责理解任务、感知外部环境、结合感知信息对任务进行分解,并做出执行策略;
“小脑”包含“VAMs(Vision Action Models)、CPG(Central Pattern Generators,中枢模式发生器,是一种神经网络,能够在没有任何来自感觉反馈或更高控制中心的节奏输入的情况下产生协调的节奏活动模式)以及其他的一些控制算法,负责运动控制,在大脑的策略下实现机器人动作的执行和反馈,其能力可以简单概括为“三岁小孩都可以做到的运动控制以及对物体的操作”,类似膝跳反射、手被针扎后缩回等反应。
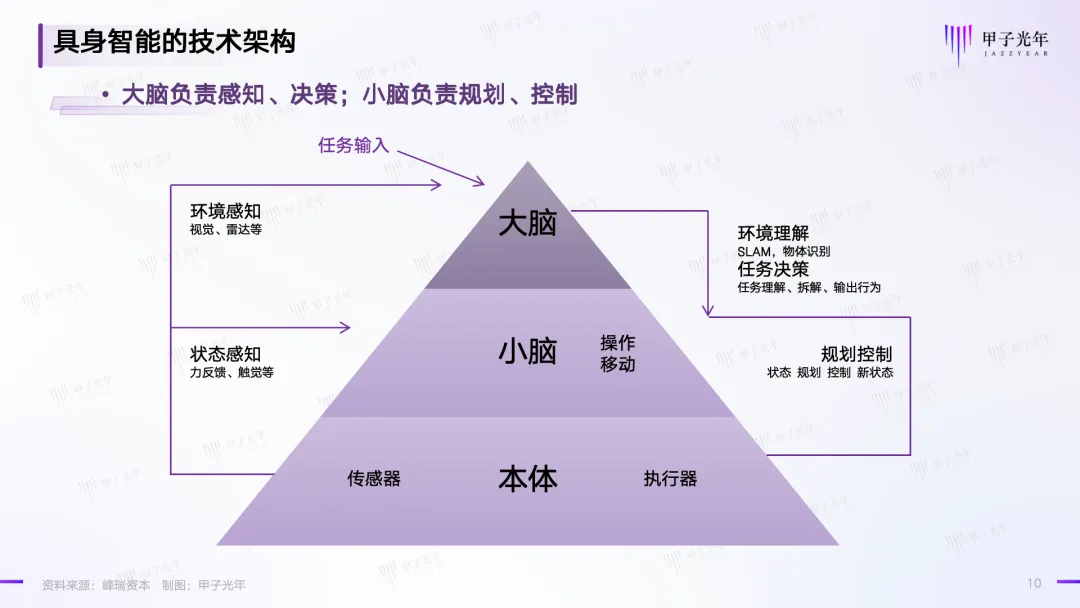
具身智能的技术架构,资料来源:峰瑞资本,制图:甲子光年
目前,得益于多模态大模型技术的进展,“大脑”领域的技术已经发展的非常成熟,也不太存在数据匮乏的问题;而“小脑”,则是目前具身智能机器人的主要技术瓶颈。
为什么“小脑”是主要瓶颈呢?原因在于,大脑和身体要进行“强绑定”。
传统的工业机器人没有大模型这样的“大脑”,一直都是靠控制器驱动的。人通过手工编程输入控制器;控制器将检测到的输入信号与设定值信号进行比较,并对偏差信号进行运算,然后将运算结果输出到执行器;执行器改变操纵变量再输出到被控对象,进而完成机器人运动的操纵。
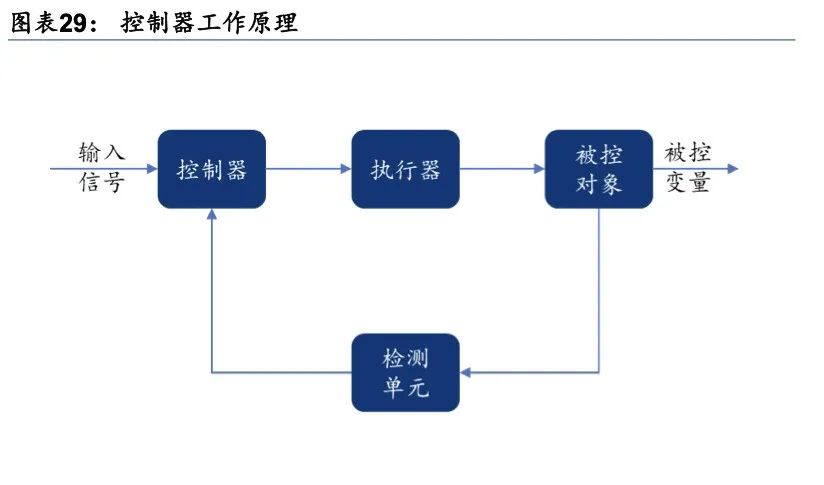
控制器工作原理,资料来源:《工业机器人基础,图片来源:华泰证券》
大模型浪潮到来之后,很多人想当然地认为,LLM和多模态模型可以作为机器人的“大脑”,只要给机器人安装上一个大模型,它就变成了智能化的机器人,可以跟随人的指令自由地做各种动作。然而,人们经过多次失败的试验后发现,这种想法是错误的,大模型和机器人本体之间,必须要有一层“驱动”机器人运动的东西,也就是将大模型(软件)和机器人本体(硬件)进行“强绑定”的东西。这个“强绑定”的东西,就是运动控制算法,也就是我们所说的具身智能机器人的“小脑”。
清华大学交叉信息研究院助理教授、清华大学具身智能实验室负责人许华哲曾经举过一个小猫的例子:把小猫绑起来让它天天看别的小猫在电视里面走来走去,然后把它放下来,你会发现这只小猫是不会走路的。这个例子说明,“智能”这件事跟“具身”是一个强耦合、强绑定的关系。
这还说明了为何加入大模型后具身智能机器人“小脑”领域的控制算法变得那么难——小脑要解决的是用LLM驱动机器人或机械臂的“prompt”问题,但受限于大模型感知能力有限、触觉传感器应用不足、手部结构相对刚性等问题,这个“prompt”十分难设计。目前主流的控制算法只能驱动机械臂做运动,但无法让机械臂像生物体那样多个自由度地自然活动;能让机器人快速移动,但无法保持平衡;能很好地完成单一任务,但无法让机械臂自动调整动作模式。
因此,如何设计出好的prompt(运动控制算法),成为了当前具身智能工业机器人的核心问题。
3.算法之囿:技术路线还未收敛
要理解控制算法的难点,首先就要了解控制论发展的历史。
几十年来,控制理论经历了以频率法和根轨迹法为主要方法的经典控制理论阶段、以线性代数理论和状态空间分析法为基础的现代控制理论阶段,如今来到了人工智能、系统论、信息论、自动控制、运筹学等多学科综合高度集成的智能控制理论阶段。
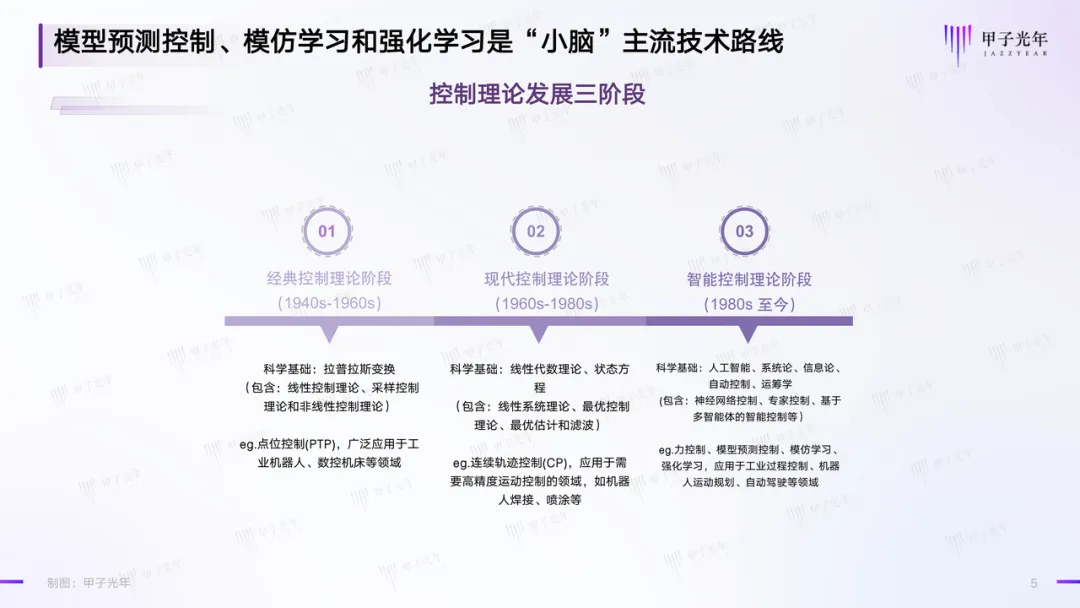
控制理论发展三阶段,制图:甲子光年
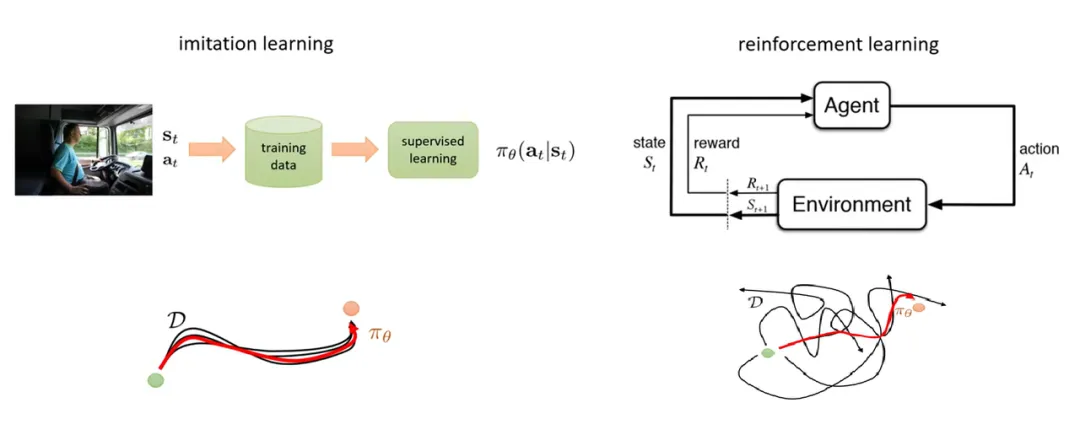
传统的工业机器人多采用点位控制(PTP)、连续轨迹控制(CP)等前两个阶段的控制算法来实现,而具身智能工业机器人,则多采用模型预测控制(Model Predictive Control, MPC)、模仿学习(Imitation Learning,IL)、强化学习(Reinforcement Learning,RL)等智能化时代的控制算法来实现。这三种方法,也是当前具身智能“小脑”领域最主流的技术路线。
这其中,模型预测控制(下文简称“MPC”)的核心思想是基于系统的当前状态,利用数学模型预测未来一段时间内的系统行为,然后通过优化算法找到一个最优的控制策略,使系统在未来的行为尽可能接近目标状态。
相比于传统的控制方法,MPC能够在复杂环境中实现更高效、更安全的控制。早在大模型出现之前,模型预测控制的方法就被泛应用,比如波士顿动力的机械狗,它通过Model(一个写死的程序)来控制机械狗做上抬关节、脚落地等动作;特斯拉的FSD技术也采用了MPC的方法。
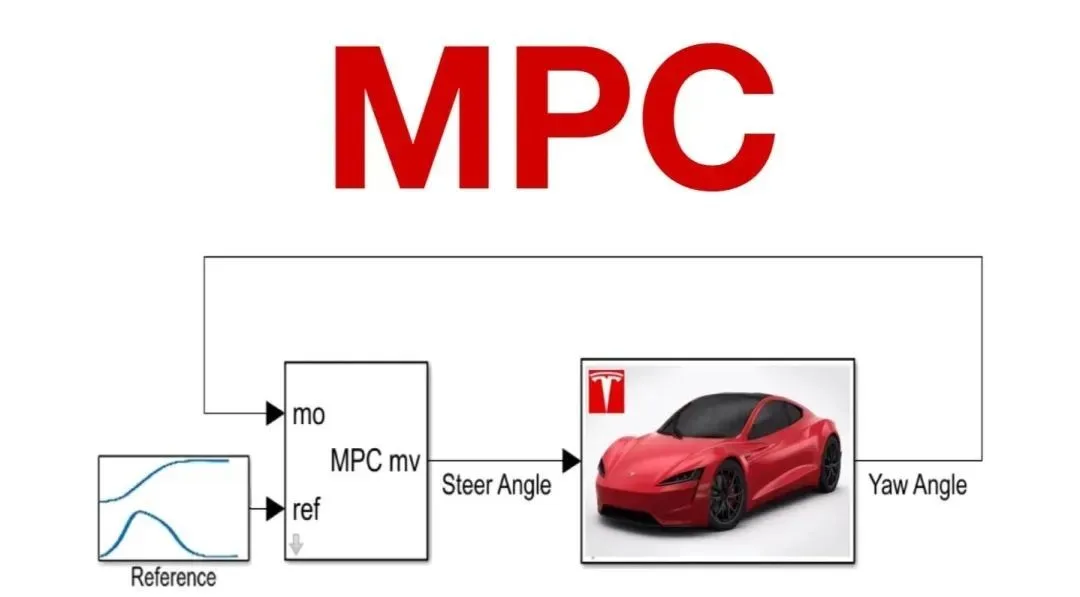
MPC示意图,图片来源:言若记
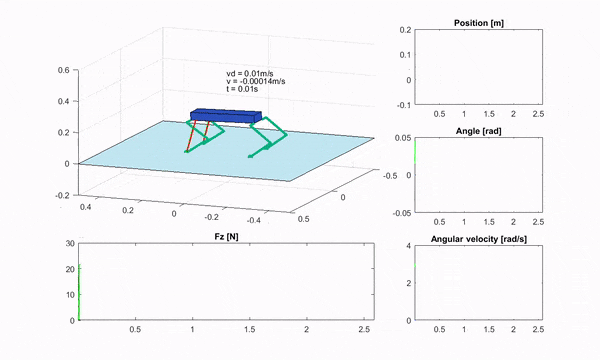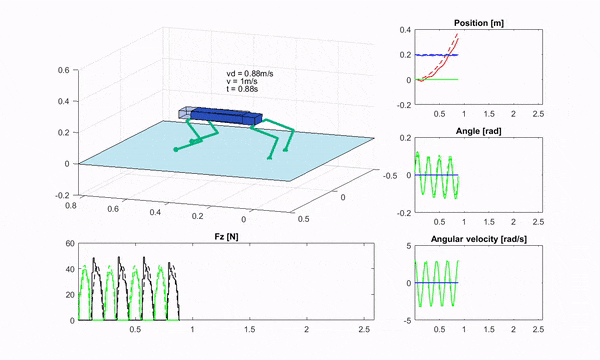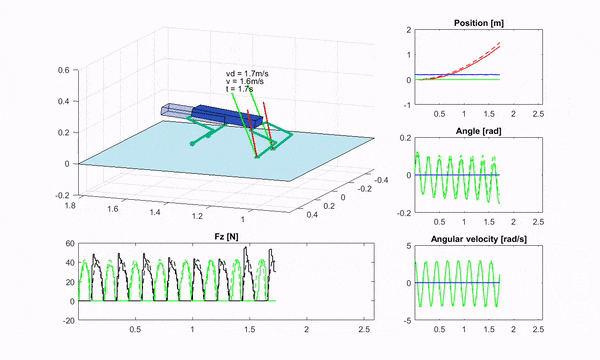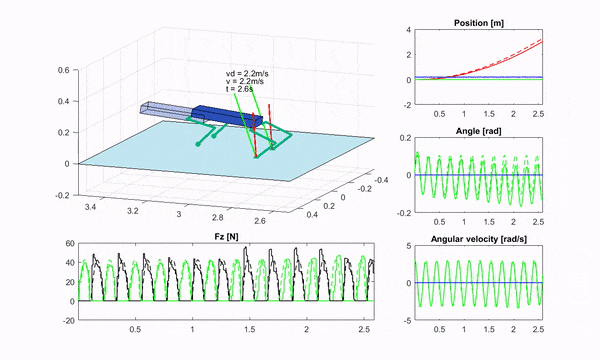
四足机器人上的 RF-MPC,图片来源:机器人规划与控制研究所
而强化学习和模仿学习,则是随着机器学习的发展而出现的。
强化学习可以理解通过“试错”进行学习——设想你在玩一个视频游戏,游戏中没有明确的答案,但每次你成功完成一个关卡或者收集到金币时,游戏会给你加分作为奖励;如果你失败了,则可能扣分。你通过不断尝试,记住哪些行动会带来奖励,哪些会导致惩罚,逐渐学会了如何更好地玩游戏。简言之,在强化学习中,系统通过试错来学习,得到的奖励或惩罚会指导它在未来做出更好的决策。打败围棋冠军李世石的AlphaGo就是强化学习的典型例子。
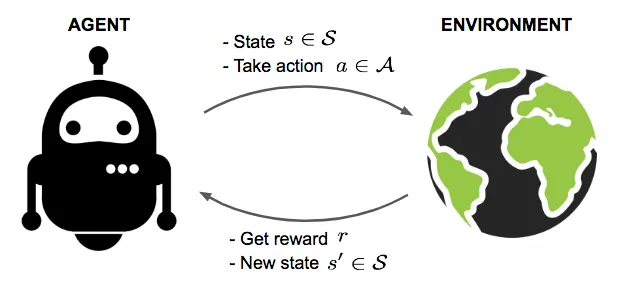
强化学习示意图,图片来源:Lil'Log《A (Long) Peek into Reinforcement Learning》
而模仿学习则可以看做是强化学习的一种特殊形式,智能体通过模仿专家的行为来学习策略,而不是通过与环境的交互试错的方法来学习——假如你在学习开车,你可能会坐在副驾驶座上看一个有经验的司机怎么操作。你会注意到他们什么时候踩油门、刹车,如何转动方向盘等。在机器人技术中,模仿学习也是让机器人通过观察人类或其他有经验的“老师”来学习如何执行特定任务。
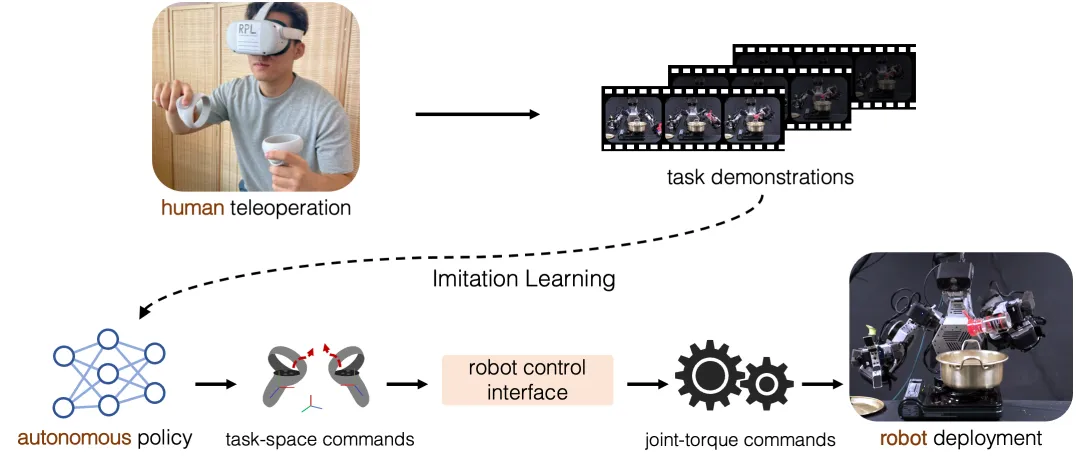
模仿学习示意图,图片来源:《Deep Imitation Learning for Humanoid Loco-manipulationthrough Human Teleoperation》
但是,这几种技术路线各有各的难点和不足:
MPC虽然可以处理复杂的动态系统,但它的灵活性相对较弱,因为它依赖于准确的模型,并且需要重新计算优化问题的解。而现实世界的工厂环境中,往往会存在大量的不确定性、非线性和外部干扰,这使得建立准确的模型变得非常困难;此外,MPC应用在机器人上时需要考虑关节限位、力矩限制等多种约束条件,比如在控制一个机械臂时,需要确保其各个关节不超过其物理限制,同时还要满足力矩和其他操作限制,这让模型算法的优化变得更加复杂。
强化学习虽然能够适应不同的任务和环境,但是其效果高度依赖奖励函数的设计,AlphaGo所处的围棋是一个封闭的场景、有明确的规则,但是工厂里不同产线的场景千变万化,设计这个奖励函数并不容易,需要反复迭代和优化;此外,强化学习在训练过程中通常需要大量的交互和数据才能达到收敛(算法找到最优策略),智能体需要不断的平衡“探索”(尝试新的动作以发现可能的更好策略)和“利用”(根据已有知识选择当前最优的动作)之间的关系,训练不稳定性强,对计算资源的消耗也比较大。
而模仿学习尽管训练速度快、收敛性好,但是它需要专家提供大量数据才能运行,但这些数据通常需要通过实际的操作来获取,采集成本非常高;同时,模仿学习的泛化能力差,即使在一部分数据集上学到了一些技能,这些技能在新环境下可能也表现不佳;模仿学习还容易出现“过拟合”,会导致模型过分专注于训练数据中的细节,而忽略了更广泛的一般性规律,导致在新环境中泛化能力较差。
模仿学习VS强化学习 图片来源:CerboAI
这些难点和不足,是制约具身智能工业机器人“小脑”发展的关键原因。
思谋科技创始人、董事长、香港科技大学讲座教授贾佳亚告诉「甲子光年」,想要知道设计工业机械臂的控制算法有多难,先看看比工业环境简单百倍的桌面环境下,控制鼠标和键盘的难度就知道了。
贾佳亚举了一个他的博士生的例子,这位博士生做的项目是让AI控制鼠标和键盘,进而统计过去十年纳斯达克所有上市公司的财报。其实拆解下来,步骤就是先让鼠标点开浏览器,进入百度、谷歌或者纳斯达克的主页去搜索,搜完之后找到数据,选中、拷贝下来,再打开Excel表格,把数据存进去。
“但就是这么简单的一件事情,我们花了一年的时间也没有完成。”贾佳亚说,“Bug出现在精确性上,比如鼠标误点了广告链接但无法回退,或者无法分辨哪些链接是已经点开过的、哪些是还没点开的,它就是反应不过来。”
贾佳亚表示,如果要让大模型做这件事情,需要做得非常快才行,就像传统的视觉检测识别,必须要做到每秒120帧的反应速度,才有可能控制机器人(指鼠标和键盘)去正常完成浏览网页、复制信息的行为。
“但现在大模型的推理速度还是比较慢的,问一句话需要想十几秒才能作答,这就决定了只靠大模型不能完成这件事,必须要结合传统的控制算法。说回工业场景,现在很多机械臂说是自己上了大模型、更加智能化,但其实都是提前编程好再去演示的。智能工业机器人的发展一定是值得期待的,但是饭得一口口吃,技术也需要按部就班地推进。”贾佳亚说。
为了寻找到更好的“小脑”,也就是具身智能机器人的控制模型和算法,学界和业界一直在积极探索。
在学界,以谷歌DeepMind、哥伦比亚大学等为代表的高校和研究机构都推出了机器人的运动控制模型。
谷歌DeepMind在2022年推出了基于Transformer结构的预训练机器人具身模型Robotics Transformer 1 (简称RT-1),它通过开放式任务无关训练和高容量架构来吸收多样化的机器人数据,以实现高效的推理速度和实时控制的可行性。RT-1的出现,解决了机器人学习中的“泛化”问题,可以在真实世界的控制中处理多样化的任务、环境和对象。
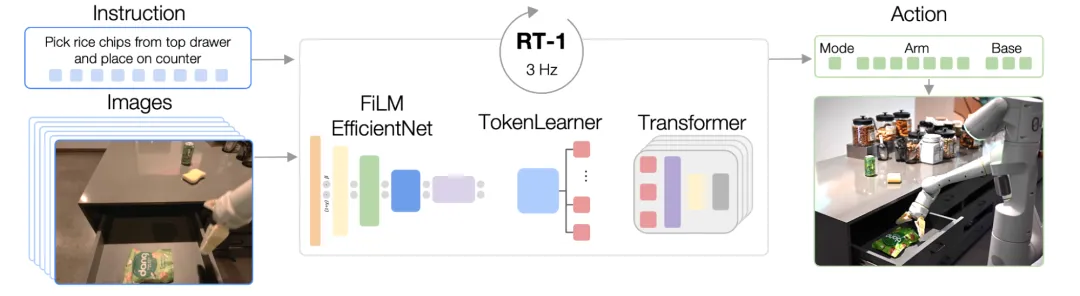
RT-1模型架构,图片来源:《RT-1: Robotics Transformer for Real-World Control at Scale》
比如,Figure 01机器人就是使用谷歌2023年3月发布的PaLM-E模型(一种具身多模态语言模型,能够不再依赖文本输入,而是训练语言模型直接获取机器人传感器数据的原始流)和RT-1的pipeline组合进行驱动的。PaLM-E先将复杂指令分解成简单指令,然后调用RT-1,进而让Figure01产生动作。
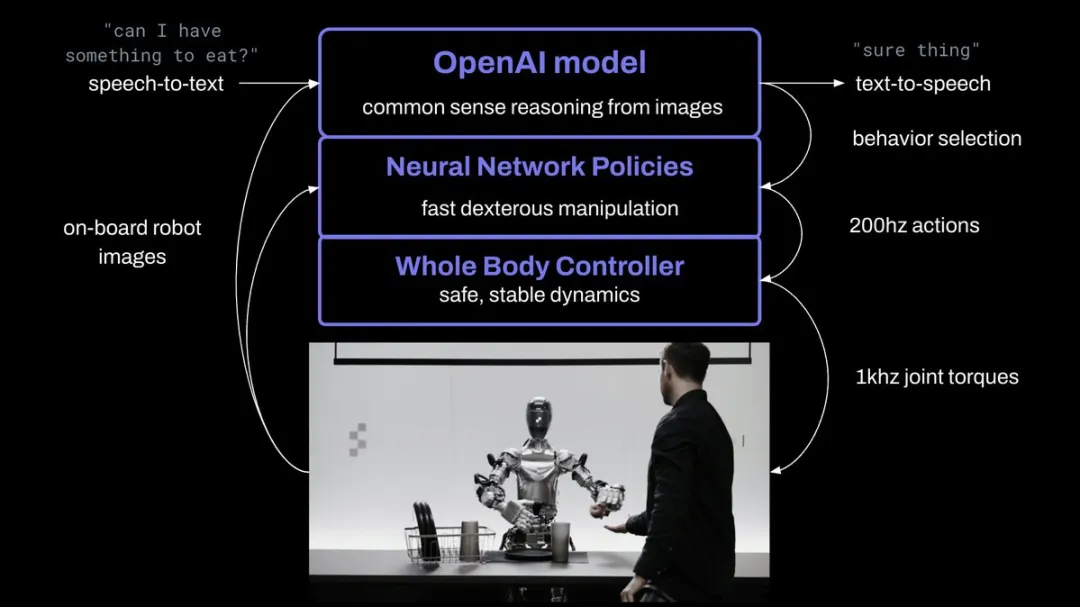
Figure 01原理解释,图片来源:Figure
但是,RT-1仅是一个能听懂简单指令的机械臂模型,只能执行拿起、放下、向左、向右等基本指令,模型中没有思维链,也不具备推理能力。于是2023年,谷歌DeepMind又推出了具身大模型RT-2,这是一个视觉-语言-动作”(vision-language-action,简称VLA)模型,是一个连接了大脑感知和小脑运动的“端到端”模型。如果说RT-1是利用预训练模型对视觉与语言进行编码,然后再通过解码器输出动作,那么RT-2则是把语言、动作、图片放在一个统一的输出空间,利用VLMs产生动作。
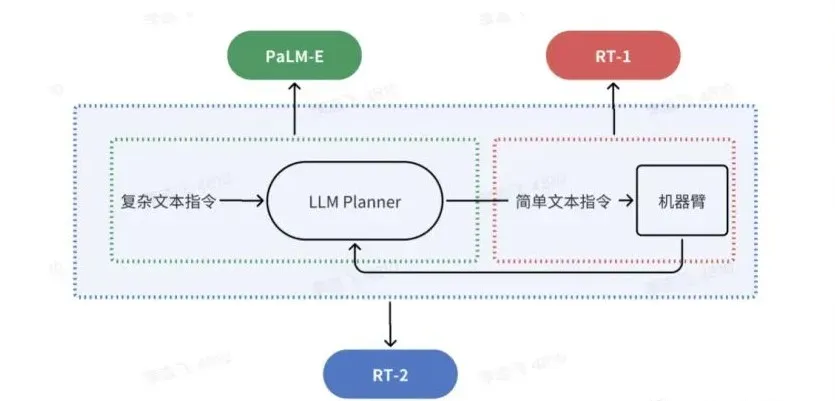
RT-1、PaLM-E、RT-2的联系和区别,图片来源:飞哥说AI
RT-2能够用复杂文本指令直接操控机械臂,中间不再需要将其转化成简单指令,通过自然语言就可得到最终的Action。
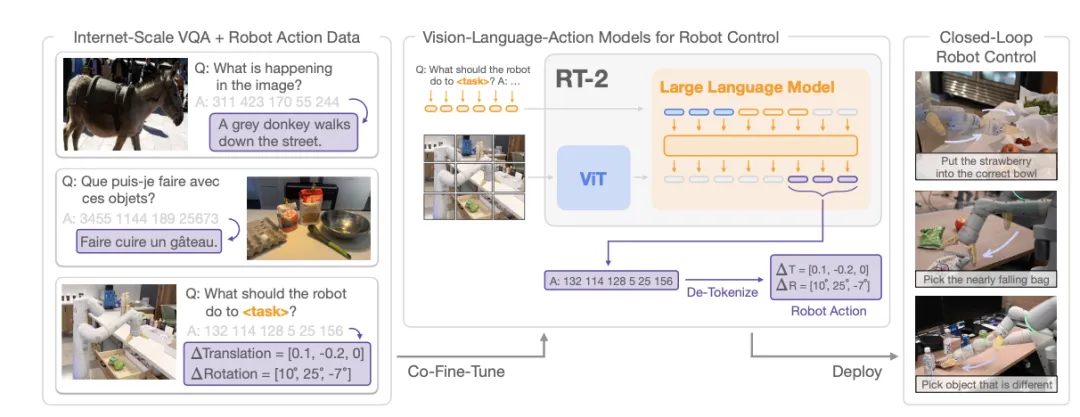
RT-2模型架构 ,图片来源:《RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control》
今年1月,谷歌Deepmind和斯坦福大学联合推出的Mobile ALOHA给大家展示了一个会做饭的机械臂,他们用不到20万人民币的成本开发了一个双臂加轮式底盘的遥操作系统,采用ACT(Action Chunking with Transformers)模仿学习算法训练。Action Chunking将独立的动作组合到一起并作为一个单元执行,采用生成式模型的方式来训练,根据输入的关节角和图像的观测值,生成预测的动作序列。
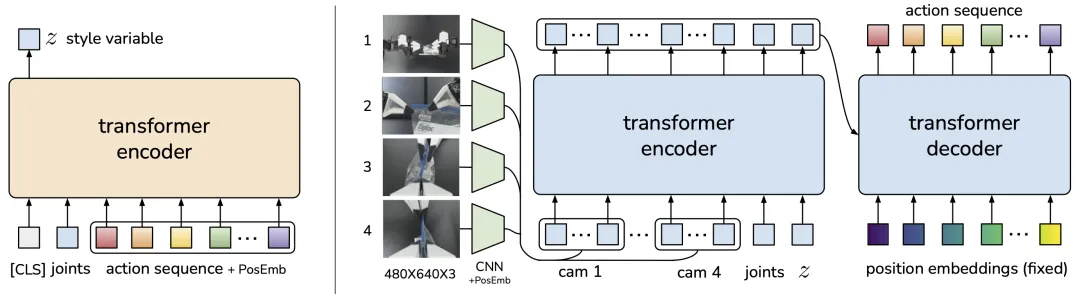
Architecture of Action Chunking with Transformers (ACT)
哥伦比亚大学宋舒然教授团队和MIT教授Russ Tedrake团队共同推出了一种新的机器人行为生成方法Diffusion Policy,它将机器人的视觉动作策略(Visuomotor Policy)表示为条件去噪扩散过程,改善了机器人在多模态分布、时序相关性和训练稳定性方面的问题,能够以稳定的速度完成给披萨抹酱、摆正各种角度的杯子等任务,动作也更加连贯。
而除了学术界,在工业界, 很多公司也在机械臂的控制算法上不断探索。
比如工业机器人巨头ABB今年发布了新一代机器人控制平台OmniCore,实现了人工智能、传感器、云计算和边缘计算系统的全面集成,它有着一流的运动性能,可使机器人达到 0.6 毫米以内的路径精度,相较前代运行速度提升了 25%,能耗降低了 20%。
“AI对整个工业行业都是一个非常大的基机遇,我们本来就做了很多大数据挖掘和预测式维护,在GenAI时代到来之后,我们又在工业机器人的自然语言对话、自然语言编程等方面做了很大推进。”ABB集团高级副总裁兼机器人中国区总裁韩晨说。

ABB新一代机器人控制平台OmniCore,图片来源:ABB
长期布局“视觉AI+机器人智能控制”的微亿智造则结合机械臂“针对对象做加工(意味着所有的动作目标均是实时生成的)”的属性,研发了基于3D GS的精细重建和八叉树实时重建结合的方案,将重建周期压缩到了60ms左右,随着相关算法优化,该方案的重建周期可以压缩到20ms,大幅度提高了机械臂的感知能力和语义理解能力——即使人任意改变被抓取物的位姿,或者改变周边环境,机械臂均可以重建刷新局部地图并迅速找到可行解。
做工业机器人本体及核心部件起家的配天机器人在2023年发布了绎零机器人运动控制引擎,该控制引擎融合了多模态技术、深度学习技术、大模型技术,能够将声音、图像、视频、力感知、速度和位姿等多模态的数据进行深度融合,可以看作是机械臂的一个“小模型”。该引擎可以使机械臂习得高动态和拟人特性的控制策略网络,能更好地适应环境变化,也提升了任务执行的精度、速度和泛化能力。目前,该引擎已经运用在了免示教焊接领域,2024世界机器人大会上那个备受瞩目的“颠乒乓球的机械臂”也出自配天之手。

2024世界机器人大会上,颠乒乓球的配天机械臂 ,图片来源:「甲子光年」拍摄
而在刚刚结束的华为全联接大会2024上,华为常务董事、华为云CEO张平安介绍,华为云与深圳前海、宝安合作成立了具身智能产业创新中心,依托盘古大模型5.0,通过云侧智能和端侧智能相结合的方式,提升了具身智能机器人在工业场景应用的精准度和泛化性——机械臂的精度从毫米级提升到微米级,将刚性零部件动态插装的成功率提升到了99.99%。

云侧与端侧模型组合解决工业场景难题,图片来源:「甲子光年」拍摄
纵然学界和业界在机器人的控制算法上做了很多尝试,但是仍然没有找到一条大家公认的最优路径。
配天机器人CTO郭涛对「甲子光年」表示,由于上述方法均有不足之处,因此业内为了互补,通常采取“模仿学习+强化学习+在仿真环境下模拟”的方式训练工业机器人,但是现在“小脑”领域的技术路线远未收敛,因此他们也在用尝试传统的算法+流行新技术结合的方式训练工业机器人。
机器人专家、清华大学自动化系博士后董云龙也表示,在具身智能机器人的操作(manipulation)也就是小脑方面,最大的问题是技术路线还未收敛、还没有像大模型的Transformer架构一样完成一个“大一统”的回归,这就需要从业者更加专注地去做研究和尝试。与此同时,由于现在强化学习只能处理一些简单的场景,业界还是用模仿学习的方法更多一点。
模仿学习的本质在于监督学习,大模型就是数据驱动的一种监督学习。那对监督学习来说,最重要的是什么呢?
没错,就是数据。
4.数据之困:数据闭环尚未形成
无论工业界还是学术界,几乎所有具身智能的从业者都有一个共识——具身智能的核心在于数据,具身智能创业公司的壁垒在于持续从物理世界获取数据并且高效使用的能力。
由于不同大语言模型(LLM)或视觉大模型(VLM)用到的文本或图像数据无法从互联网内容中获取,而需通过真实的机器人操作来采集或者高级仿真平台生成,因此具身数据的采集需要较高的时间和成本,很难达到较大的规模。
以谷歌为例,他们在Mountain Village办公室的厨房里采集了17个月,才得到了13万条数据,这13万条数据可以让机器人在谷歌的厨房里表现很好,但是一旦出了厨房,其成功率就从97%骤降到30%左右,想要提高成功率就要重新采集数据;再比如特斯拉为了实现完全自动驾驶,其车队已经行驶了30亿英里(约为48亿公里)去收集数据。
除了数据采集成本高、难度大,具身智能数据采集还有一个很大的就是问题就是没办法做到Scalable(可扩展)。各个工厂的环境千变万化、充满了不确定性,需要机器人具备高度的适应性和学习能力。由此,有些人想到了在仿真环境里去训练机器人。
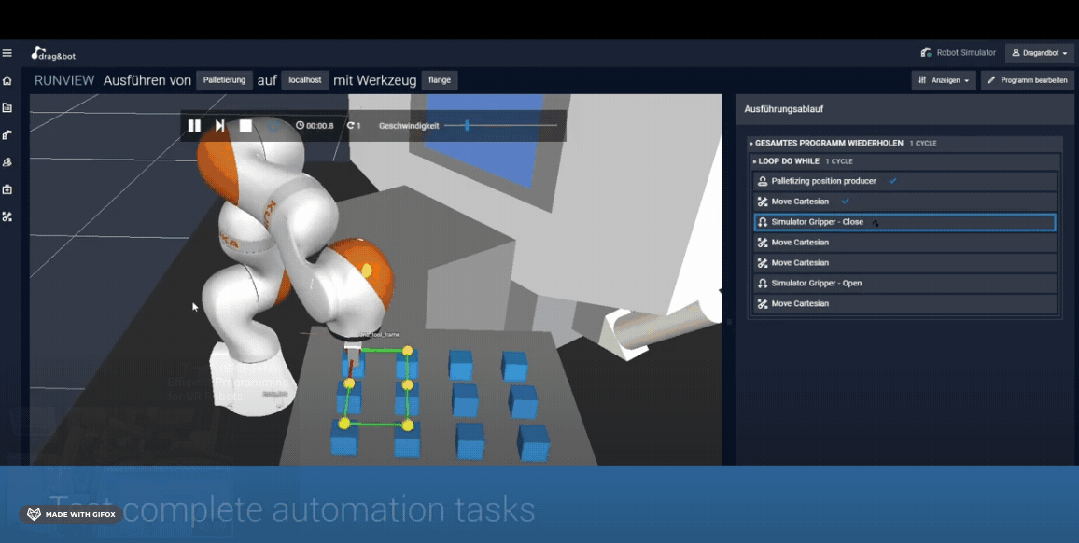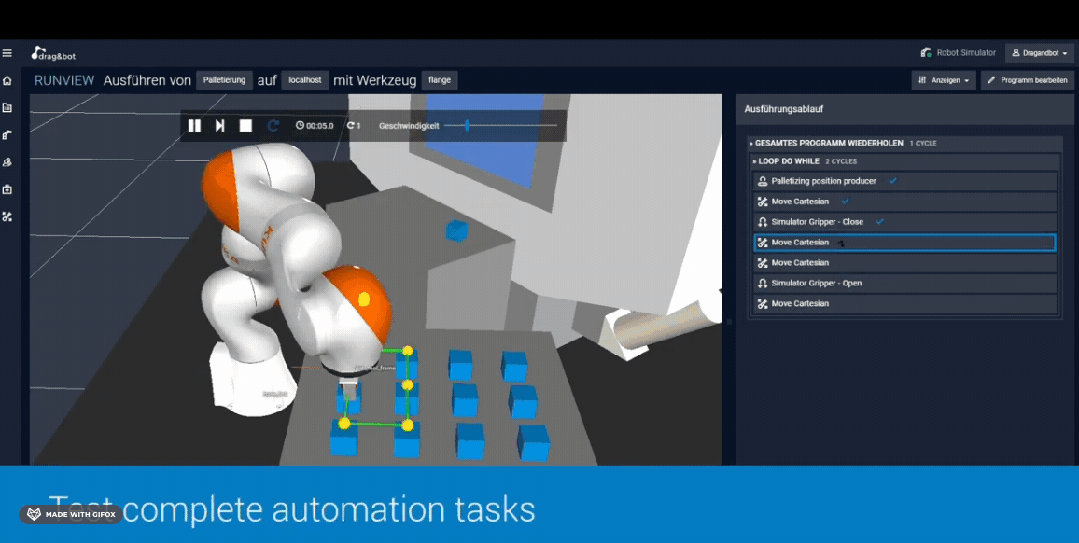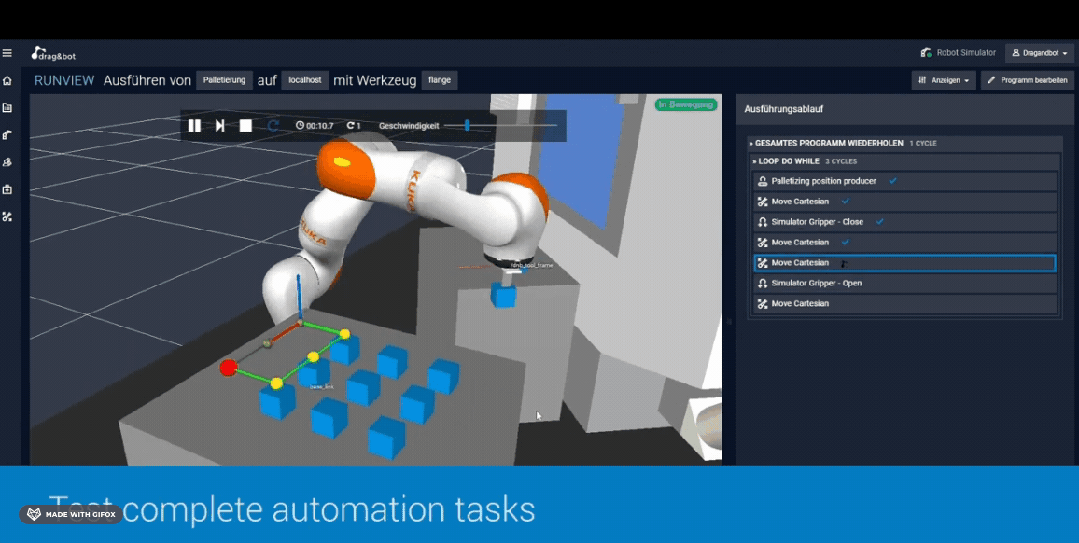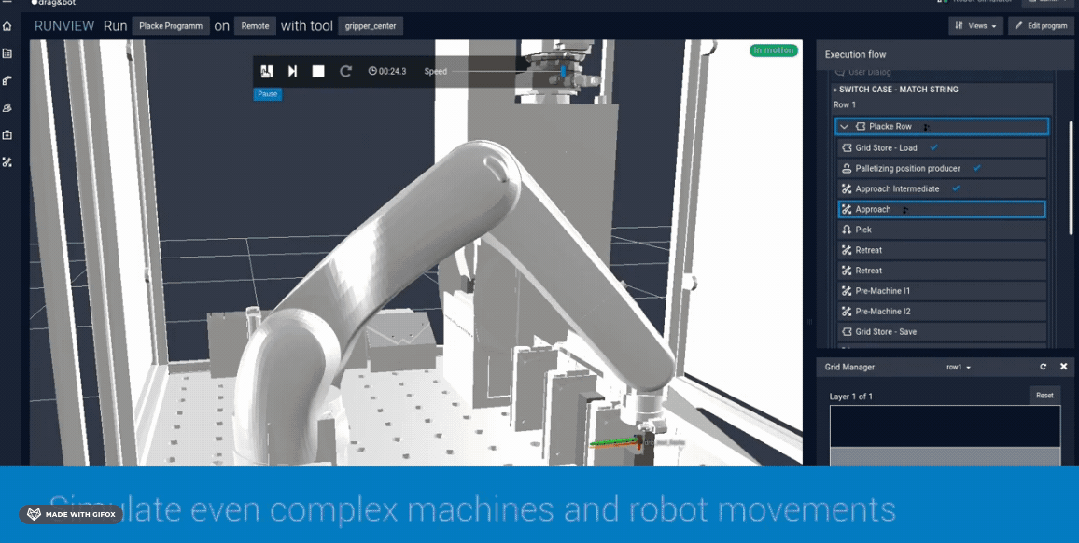
在仿真环境下训练机械臂 图片来源:drag&bot robot programming platform
通过搭建仿真环境训练机器人确实降低了数据获取的成本,灵巧手、机器狗等一些复杂的控制问题借助仿真数据和强化学习也取得了突出的成果,但是由于仿真器中的环境、感知、机器人硬件均与真实环境之间存在差距,存在Sim-to-Real Gap),可能影响机器人在真实环境中的表现;另外像鞋带、衣物等软体物品的仿真问题还亟待解决,这也限制了仿真数据在涉及到软体物品操作的应用。
本来真实数据和仿真数据就各有各的问题,而到了工业领域,在数据的获取上又加了一层难度——数据孤岛。
数据孤岛的形成,与我国制造业长期得不到有效解决的几个问题有关:
制造企业每天都会生成大量的数据,但这些数据往往分散在不同的部门和系统中,缺乏整合和分析。图片来源:讯能集思
没有数据,工业机器人就无法感知与理解环境;没有数据,就无法训练工业机器人学习不同的技能、做出不同的动作;没有数据,就无法做到“通用”和“智能”,工业机器人在不同环境下的“泛化性”和“能力迁移”也就无从谈起。
最近,「甲子光年」也看到了不少工业机器人厂商为了解决数据问题所作出的创新尝试。
微亿智造将大模型引入了工业场景数据收集的过程中,会先采集少量的真实数据,然后将这些真实数据作为语料喂给大模型,通过AIGC的方式合成一些数据。
配天机器人拥有多年做工业机器人本体的经验,他们的机器人在进厂工作的时候就可以顺道采集数据;除了真实数据,配天机器人团队还搭建了仿真的训练环境,采用强化学习算法训练机器人。比如那个颠乒乓球的机械臂,就是完全在仿真环境下训练出来的。
ABB则推出了OptiFact™,这是一款模块化软件平台,可以通过收集、管理和分析生产设施中的数据。它能够通过与车间设备的连接,从数百台工厂设备中收集数据,协助客户提取数据、进行结构化处理,确定关键指标,并在关键时刻获得准确的洞察力,从而更迅速地做出更明智的决策。此外,OptiFact™还能灵活处理数据并将其存储在任何位置,降低高达50%的IT成本,同时清理数据脉络,从而为高价值专家节约最多25%的时间。

ABB OptiFact™模块化软件平台,图片来源:ABB
此外,在具身智能的数据领域也涌现出了不少服务商。
比如艾欧智能,他们开发了动作捕捉设备和融合算法,采用多传感器融合的动作捕捉技术,雇佣外采人员采集日常活动数据,并由专业标注团队使用自研平台进行语义标注;同时,他们还拥有大量的数据采集设备,适配遥操作,可以精准匹配不同构型的机器人。
诺亦腾则是一家深耕动作捕捉技术的企业。他们基于具身智能机器人领域的实际研发需求,研发了一套基于动作捕捉技术的「人在回路」(Human-in-the-loop)解决方案。通过高精度、低时延、高频率的人类动作数据采集系统,解决方案可实现人形机器人和工业机械臂示教、工业机械臂高精度实时追踪量测、动捕遥操作、人体-机器人本体映射、工作平台适配、训练数据集生产等。

诺亦腾具身智能机器人解决方案 ,图片来源:诺亦腾
北京具身智能机器人创新中心则充分发挥产业牵头方的优势,在北京亦庄的机器人产业园内建立了大约4000平方米的机器人数据采集基地,邀请了很多公司来搭建场景,做机器人本体的入驻,比如南方电网就在此搭建了工业巡检的场景。“长程任务规划、灵巧操作、定位导航、全身运动控制等都可以用到我们的数据。”北京具身智能机器人创新中心数据负责人李广宇说。
然而,即使第三方供应的数据再便宜、再优质,对具身智能企业来说,形成自己的数据闭环都至关重要。正如曹巍在《对话蓝驰创投合伙人曹巍:大模型和工业机器人结合不是伪命题》一文中所说,优秀的公司会形成自己的数据闭环、硬件闭环和算法闭环。
那对具身智能工业机器人来说,数据闭环的起点在哪呢?
在赵何看来,或许是工业互联网。
“工业互联网发展了好多年,之前好像一直都很热闹,现在到了一个非常尴尬的时期。但在我看来,工业互联网的历史使命可能就是为工业大模型收集数据”,赵何说,“就像ChatGPT是之前用消费互联网的数据训练成的,但是当时没有人知道以后会出来一个ChatGPT,也没有人有意识地专为ChatGPT收集互联网上的数据,一切都是历史的巧合。工业互联网在冥冥之中,或许也会复现这一历史走向,虽然现在看起来工业互联网进入了一个发展的迷茫期,但未来有一天或许会因为具身智能工业机器人而重新爆发。”
清华大学交叉信息研究院助理教授&清华大学MARS Lab负责人赵行则认为,数据最后会形成一个“金字塔”,这个金字塔里面有互联网数据、仿真数据、真实世界采集的数据、在线调整的数据。要想训练好一个有通用性的机器人模型,就需要设计一条路径,明确规定在什么时候采集什么样的数据——多少依赖仿真、多少依赖真实,或者把真实数据放到仿真器里做随机化和增强,这条路径的设计是一个技术问题。
“DALLE-3论文里告诉我们,百分之九十五是一个黄金比例,95%的意思是说手动标5%,剩下95%通过数据飞轮自己去生成筛选。反之,100%的真实数据标不动,标不起;100% 生成数据让模型表现的很差。这个里面有很多技术性的,也有经验性的东西组合在一起,很难用一句话回答,但我觉得需要找到一个好的数据路径去达到终局。”在一次播客的采访中,赵行说。
而终局是什么?具身智能工业机器人概念提出者赵何有着乐观的预测:“具身智能工业机器人的诞生和历史使命就是接管人类社会物质资料的生产,为人类的发展提供持续的物质支持,这也是它唯一的历史归宿。”
(封面图来源:「甲子光年」使用AI工具生成)

 2024-09-30
2024-09-30

 4599
4599 0
0 0
0 0
0
